L’étude ci-dessous visent à répondre aux grandes questions que nous nous posons tous dans le cadre du Generative Engine Optimization :
- Comment les LMMs se sourcent ?
- En combien de temps ChatGPT, Gemini et Perplexity intègrent un nouveau contenu ?
- Obsolescence des contenus dans l’IA : combien de temps ChatGPT, Gemini et Perplexity continuent-t-ils de citer une page ?
- Autorité de domaine et IA : pourquoi les LLMs citent plus vite les sites à forte autorité ?
- IA et actualisation des contenus : quelle est la vitesse réelle de mise à jour de ChatGPT, Gemini et Perplexity ?
- Comment ChatGPT, Gemini et Perplexity intègrent et conservent les contenus du web ?
| L’étude repose sur une collecte réalisée à l’automne 2025, entre la dernière semaine de septembre et la première d’octobre. Elle correspond donc à une photographie à un instant t, un état momentané du comportement des modèles, plutôt qu’à une tendance structurelle. Cette étude s’inscrit dans une perspective exploratoire de compréhension du comportement des modèles génératifs à grande échelle (LLMs) face aux dynamiques de fraîcheur, d’autorité et d’obsolescence du web. Elle vise à identifier les mécanismes par lesquels les modèles sélectionnent, conservent ou abandonnent certaines sources au fil du temps, un phénomène central dans le champ émergent du Generative Engine Optimization (GEO). Cette prudence s’impose: la période d’observation est courte, et les LLMs évoluent à un rythme rapide. Nos résultats doivent ainsi être compris comme une observation ponctuelle d’un système en évolution, mettant en évidence des tendances structurelles plutôt que des valeurs numériques. De plus, nous faisons appel à des proxies (voir onglet méthodologie), c’est-à-dire à des mesures indirectes destinées à approcher un phénomène qu’il est difficile d’observer directement. |
Fraîcheur lors de la citation

Le graphique illustre la fraîcheur des sources citées par les LLM, selon leur date de dernière mise à jour (updated_at).
Les résultats montrent que :
● 66.7 % des citations proviennent de contenus mis à jour depuis moins d’un an, dont environ :
○ 21.7 % ont été mis à jour il y a moins d’un mois,
○ 23.2 % entre 1 et 6 mois ;
○ 21.8 % entre 6 et 12 mois ;
● 11.7 % des sources datent de 1 à 2 ans ;
● Les contenus plus anciens (plus de 5 ans) représentent 10.1 % des citations. Interprétation
La distribution temporelle des citations montre que plus des deux tiers des contenus mobilisés par les LLMs ont moins d’un an, ce qui traduit une sensibilité marquée à la fraîcheur des données disponibles en ligne.
Cependant, la présence d’environ 10 % de contenus âgés de plus de cinq ans indique que les modèles conservent un socle de connaissances stables. Nous pouvons supposer que cela provient principalement de contenus “evergreen”, c’est-à-dire d’informations pérennes, ou de pages à forte autorité, encore jugées pertinentes malgré leur ancienneté.
Nous verrons dans la suite de notre analyse que l’obsolescence du contenu est effectivement liée à l’autorité du domaine, confirmant que les sources les plus crédibles tendent à demeurer citées plus longtemps par les LLMs.
Ce résultat reste stable lorsque l’on considère différentes fenêtres temporelles (par exemple, en resserrant l’analyse sur les six derniers mois), ce qui suggère que la relation entre fraîcheur et autorité est structurelle et non conjoncturelle.
Première Citation (via le proxy)

La figure ci-dessus présente la valeur du proxy de première citation (voir méthodologie). Pour le résumer en termes moins techniques, ce proxy correspond à la valeur minimal observé dans notre jeu de données entre la date la citation par le modèle et de publication du contenu , en excluant les valeurs extrêmes.
Il est important de préciser qu’il s’agit ici d’un indicateur de mobilisation par le modèle, et non d’une intégration structurelle dans ses poids : le proxy mesure le délai entre la disponibilité d’un contenu en ligne et sa première apparition dans une réponse générée.
Ce proxy nous offre un ordre de grandeur de la vitesse d’intégration des nouvelles sources par les modèles.
Le délai observé de neuf jours, montre que les LLMs intègrent les contenus récents en moins de deux semaines, ce qui témoigne d’une forte réactivité dans la mise à jour de leurs citations.
Effet de l’autorité du domaine

La figure ci-dessus présente la valeur du proxy de première citation appliquée à chaque catégorie d’autorité. Elle met en évidence un lien clair entre l’autorité du domaine et la rapidité de première citation. Les valeurs observées sont les suivantes :
● Pour les citations provenant de domaines à faible autorité, nous observons une valeur de proxy de quinze jours
● Pour les citations provenant de domaines à autorité moyenne, la valeur du proxy se situe à dix jours
● Pour les citations provenant de domaines à forte autorité, la valeur du proxy est réduite à huit jours.
Cette tendance confirme que les contenus issus de sites à forte autorité sont intégrés et cités plus rapidement par les modèles, probablement en raison de leur visibilité accrue, de leur fréquence de mise à jour plus élevée et des signaux de confiance qu’ils véhiculent.
Ce résultat est cohérent avec les observations issues du référencement classique, où la fréquence de crawl et la probabilité d’indexation augmentent avec l’autorité de domaine, renforçant l’hypothèse d’un biais de visibilité hérité dans les modèles génératifs.
Différences entre modèles
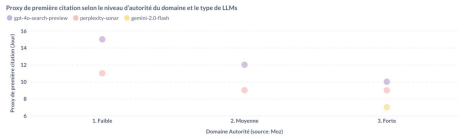
[Note : Nous disposions de moins de 50 citations pour calculer le proxy de première citation de Gemini dans les catégories de faible et moyenne autorité.
Ces échantillons, jugés trop faibles, n’ont donc pas été inclus dans ce graphes]
En suivant la même approche méthodologique, nous avons cette fois décliné l’analyse selon les différentes tranches d’autorité de domaine, ainsi que selon les différents LLMs.
Les valeurs de proxy montrent que l’autorité du site influence de manière similaire l’ensemble des modèles : plus un domaine est reconnu, plus son contenu est intégré rapidement dans les citations.
À noter que, dans le cas de GPT-4o, nous observons un léger décalage temporel par rapport aux autres modèles : il semble accuser quelques jours de retard dans la citation de nouveaux contenus.
Cette observation suggère que GPT-4o intègre les nouvelles sources plus lentement que les autres modèles analysés.
Ces différences inter-modèles pourraient refléter non seulement des vitesses d’indexation distinctes, mais aussi des stratégies de sourcing divergentes (reposant sur des bases documentaires internes, des API externes ou des couches de recherche temps réel).
Conclusion
Globalement, le proxy de première citation met en évidence l’intégration rapide des nouveaux contenus par les LLMs. Il souligne la capacité des LLMs à s’adapter rapidement au flux d’informations du web.
Par ailleurs, la provenance des sources, et plus particulièrement le niveau d’autorité des domaines, exerce un impact significatif sur la rapidité de citation. Plus une source provient d’un domaine à forte autorité, plus elle est prise en compte rapidement, et ce quelle que soit la famille de LLMs considérée.
Obsolescence (via le proxy)
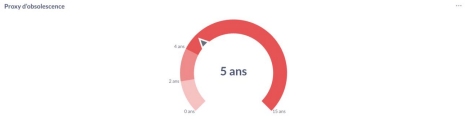
La figure ci-dessus présente la valeur du proxy d’obsolescence (voir méthodologie). En termes moins techniques, ce proxy correspond à l’écart maximal observé dans notre jeu de données entre la date de citation par le modèle et la dernière mise à jour du contenu ,en excluant les valeurs extrêmes. A noter, Dans le cas du proxy d’obsolescence, nous avons adopté une approche plus conservative, en nous appuyant sur la tendance du percentile P90, afin de dégager une tendance générale et de limiter l’influence de groupes spécifiques.
Ce proxy met en évidence les contenus les plus anciens encore actifs dans les citations des modèles. Le recours au percentile P90 isole la queue supérieure de la distribution, les cas extrêmes où des contenus anciens continuent d’être cités, tout en limitant l’influence des valeurs aberrantes.
Ce proxy ne représente pas une date précise, mais agit comme un miroir du “temps d’obsolescence d’une source”, c’est-à-dire un indicateur de la durée pendant laquelle un contenu demeure exploité malgré son ancienneté et son l’absence de mise à jour.
La valeur observée de cinq ans, montre que les LLMs s’appuient encore beaucoup sur des contenus anciens, non mis à jour depuis plusieurs années. Cette observation suggère que, malgré leur capacité à intégrer rapidement de nouvelles informations, les modèles conservent un socle de connaissances stables et durables, issu de sources plus anciennes et établies
Effet de l’autorité du domaine
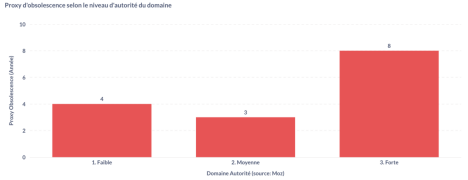
Comme pour le proxy de première citation, nous avons utilisé la même méthodologie et avons réitéré le calcul du proxy d’obsolescence, en le déclinant cette fois selon différentes tranches d’autorité de domaine.
La figure ci-dessus présente la valeur du proxy d’obsolescence appliquée à chaque catégorie d’autorité. Elle met en évidence un comportement similaire des LLMs pour les domaines à faible et moyenne autorité, mais une différence marquée pour les domaines à forte autorité. Les valeurs observées sont les suivantes :
● Pour les domaines à faible et moyenne autorité, la valeur du proxy se situe dans une tranche comprise entre trois et quatre ans ;
● Pour les domaines à forte autorité, la valeur du proxy atteint environ neuf ans.
Cette disparité suggère que les modèles conservent et citent plus longtemps les contenus issus de domaines à forte autorité, probablement en raison de leur crédibilité établie, de leur capacité à rester utiles et fiables dans le temps et des signaux de confiance qu’ils véhiculent.
Cette persistance accrue pourrait résulter d’un effet combiné entre la réputation du domaine et la densité de backlinks, deux signaux que les modèles semblent implicitement valoriser dans leurs représentations internes.
Différences entre modèles
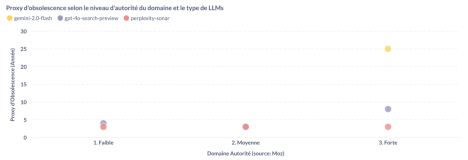
Toujours en suivant la même approche méthodologique, nous avons cette fois décliné l’analyse du proxy d’obsolescence selon les différentes tranches d’autorité de domaine et les différents modèles de langage (LLMs).
Le graphique ci-dessus montre que les modèles présentent des comportements similaires pour les domaines à faible et moyenne autorité, tandis qu’ils divergent nettement pour les domaines à forte autorité.
– Les valeurs du proxy d’obsolescence se situent entre trois et quatre ans pour l’ensemble des modèles et pour les domaines à faible ou moyenne autorité.
– En revanche, les écarts sont beaucoup plus marqués pour les domaines à forte autorité: Gemini 2.0 Flash à une valeur de proxy de vingt-cinq ans, ChatGPT de huit ans, alors que celle de Perplexity est de trois ans.
Cette divergence importante suggère que, si les LLMs adoptent des comportements homogènes pour la majorité des sources provenant de domaine d’autorité faible et moyenne, leurs dynamiques de conservation du contenu diffèrent lorsqu’il s’agit de domaines à forte autorité.
Ces différences ne doivent toutefois pas être interprétées comme des écarts de performance, mais comme des variations d’architecture et de stratégie de sourcing : Perplexity, par exemple, s’appuie sur une couche de recherche active en temps réel, tandis que Gemini semble davantage capitaliser sur des corpus établis.
Ce résultat semble cohérent : Perplexity a en effet la réputation de favoriser le contenu récent, privilégiant les sources fraîchement publiées.
À l’inverse, Gemini adopte une approche différente, en accordant une plus grande tolérance aux sources établies, même lorsqu’elles n’ont pas été mises à jour depuis longtemps.
Limites et perspectives
Les résultats présentés reposent sur un instantané de courte durée (automne 2025) et sur un échantillon limité à quelques milliers de citations. Leur portée doit donc être comprise comme exploratoire. De futures itérations du protocole, réalisées sur plusieurs périodes et avec un volume de prompts élargi, permettront de confirmer la stabilité des tendances observées.
Conclusion
En conclusion, le proxy d’obsolescence montre que des contenus anciens et non mis à jour peuvent toujours être cités par les LLMs.
Cependant, cette durée est fortement influencée par l’autorité du domaine : les pages issues de sites reconnus sont conservées et citées beaucoup plus longtemps que celles provenant de domaines à autorité moyenne ou faible. A noter, les modèles présentent des comportements globalement similaires, mais affichent un curseur différent lorsqu’il s’agit de sources à forte autorité.
Ces observations confirment que, dans l’écosystème informationnel des LLMs, l’autorité du domaine prolonge la durée de vie du contenu, même en l’absence d’actualisation récente, mais que l’ampleur de cette persistance est liée aux types de modèles.
Ces résultats constituent un socle empirique pour les travaux futurs sur la visibilité et la durabilité des sources dans les environnements d’intelligence générative, et participent à la formalisation du champ du Generative Engine Optimization (GEO).
Méthodologique
Construction des proxys
Notion de “proxy”
Dans ce cadre, un proxy désigne une mesure indirecte utilisée pour approcher un phénomène qu’il est impossible d’observer directement. En effet, nous ne pouvons pas déterminer avec certitude le moment où un contenu devient réellement obsolète, ni la date exacte à laquelle il est intégré pour la première fois dans les bases de connaissances des modèles de langage (LLMs).
Nous utilisons donc des variables temporelles observables, la date de publication (published_at), la date de mise à jour (updated_at) et la date de citation (referenced_at), pour construire deux proxys :
● Proxy d’obsolescence → mesure l’écart “maximal” observé dans notre jeu de données entre la date de citation par le modèle (referenced_at) et la dernière mise à jour du contenu (updated_at), après exclusion des valeurs extrêmes.
● Proxy de première citation → mesure l’écart “minimal” observé dans notre jeu de données entre la date de citation par le modèle (referenced_at) et la date de publication du contenu (published_at), après exclusion des valeurs extrêmes
Ces proxys traduisent des comportements structurels du web et des modèles :
● la réactivité du LLMs à intégrer du nouveau contenue,
● et la longévité du contenu sur lequel les modèles s’appuient.
Des tests exploratoires sur d’autres sous-échantillons ont confirmé la stabilité de ces proxys, avec des écarts inférieurs à ±10 % sur les valeurs médianes observées, ce qui suggère une bonne robustesse statistique malgré la taille limitée de certains jeux de données.
Pourquoi analyser les “queues” de distribution
La majorité des contenus cités par les modèles se situent dans une fourchette comprise entre six mois et quatre ans. Néanmoins, à l’image de tout phénomène distribué, certaines observations extrêmes se distinguent :
● Certains citations sont extrêmement récentes (fraîchement publiées et indexées) ● Tandis que d’autres sont très anciennes (contenu non mis à jour depuis plus années mais encore cités)
C’est précisément dans ces extrêmes, les “queues” de la distribution, que se trouvent les signaux les plus révélateurs. C’est pourquoi se limiter à la moyenne ou à la médiane masquerait ces dynamiques essentielles : ces mesures décrivent le comportement central, alors que notre objectif est de comprendre les extrêmes, là où se joue réellement le cycle de vie du contenu.
Ce choix méthodologique s’aligne sur les pratiques de l’analyse de risque ou des phénomènes extrêmes, où la compréhension des queues de distribution est plus informative que les valeurs centrales.
● La queue gauche (valeurs les plus faibles) illustre la rapidité d’apparition du nouveau contenu, autrement dit la première citation ;
● La queue droite (valeurs les plus élevées) révèle la persistance du contenu ancien, donc l’obsolescence.
Choix des percentiles et cadre temporel
| Proxy Obsolescence | Proxy de Premiere Citation | |
| Principe | Mesure la queue droite de la distribution : les 10 % de citations les plus anciennes. | Mesure la queue gauche : les 5 % de pages les plus récentes citées. |
| Calcul | referenced_at – updated_at | referenced_at – published_at |
| Percentile | P90 | P5 |
| Fenêtre Temporelle | Pas de restriction de période | 6 derniers mois |
| Justification | Ce percentile capture les contenus obsolètes encore cités par les LLMs. Le P90 offre un indicateur robuste, peu sujet aux influence de groupes spécifiques | Ce percentile révèle la rapidité d’intégration du nouveau contenu dans les bases des modèles. La restriction à 6 mois garantit une analyse centrée sur les dynamiques de première citations. Le P5 reflète la réactivité des modèles, c’est-à dire leur capacité à identifier et intégrer rapidement les contenus les plus récents après leur mise en ligne. |
Pour rappel:
Un percentile (ou quantile) est une mesure statistique qui divise une distribution en cent parts égales. Il indique la valeur en dessous de laquelle se situe un certain pourcentage des observations.
Ainsi, le P50 correspond à la médiane, c’est-à-dire la valeur centrale qui sépare la moitié inférieure et la moitié supérieure des données.
De la même manière, le P5 et le P90 représentent respectivement les valeurs proches des extrêmes inférieurs et supérieurs de la distribution : le P5 correspond à la valeur sous laquelle se trouvent 5 % des observations, et le P90 à celle sous laquelle se trouvent 90 % des observations.
En synthèse
● Un proxy permet d’observer indirectement des comportements invisibles (obsolescence ou première citation).
● L’analyse des queues de distribution (gauche et droite) est essentielle pour saisir les phénomènes extrêmes :
○ P90 (queue droite) → mesure la stagnation et la persistance du vieux contenu.
○ P5 (queue gauche) → mesure la réactivité et la vitesse de première citation du nouveau contenu.
Construction des Datasets
Unité d’analyse et taille des datasets
L’unité d’analyse est la citation : une source retournée par un modèle à une date t. Chaque citation est donc rattachée à un prompt précis et à un moment d’exécution du LLM. Au total, 2000 prompts ont été générés, produisant 15,415 citations.
Sur ce total :
● 12,475 citations ont été retenues pour l’étude sur la fraîcheur et l’obsolescence
● 676 citations ont été retenues pour l’étude sur la première citation
Pour chaque dataset, nous sommes limité aux citations ayant les dates que nous cherchions à analyser ( referenced_at et updated_at, referenced_at ou published_at)
Récupération de l’autorité de domaine
Pour chaque citation, nous avons cherché à évaluer l’autorité du domaine source. Nous avons utilisé l’API Moz, une référence reconnue dans le domaine du référencement, qui attribue à chaque domaine un score d’autorité compris entre 0 et 100.
Afin de faciliter l’interprétation des résultats, nous avons classé les domaines en trois niveaux :
● Faible autorité : de 0 à 29
● Autorité moyenne : de 30 à 59
● Forte autorité : de 60 à 100
Récupération et validation des dates
Dans cette étude, la question de la datation des contenus s’est rapidement imposée comme un enjeu central.
Chaque source citée, c’est-à-dire chaque page web référencée par un LLM, comporte, en théorie, trois repères temporels distincts :
● la date de première mise en ligne du contenu, autrement dit son âge d’origine ( que nous appellerons published_at )
● la date de dernière actualisation ou modification de la page (que nous appellerons updated_at )
● La date de citation (referenced_at)
Dans la pratique, les sites publient, modifient et republient sans toujours mettre à jour leurs métadonnées. Certains ne fournissent aucune indication temporelle, d’autres mélangent les deux notions, rendant leur interprétation incertaine.
Il revient donc à des outils externes, des librairies spécialisées, de tenter de retracer ces dates à partir d’indices indirects : balises HTML, empreintes textuelles, structures d’articles ou encore métadonnées d’images.
Nous avons utilisé HTMLDate, une librairies déployée en prod pour pour extraire ces dates d’une page web
Cependant, la variable published_at s’est révélée particulièrement sensible.
Cette sensibilité justifie notre décision de privilégier les sources récentes et de multiplier les vérifications croisées, afin de minimiser le risque de confusion entre simple rafraîchissement et véritable première publication.
Elle peut être facilement faussée, notamment lorsque certains sites utilisent à tort le métatag published_at pour indiquer la date de mise à jour et non celle de première publication.
Cette confusion est fréquente : elle brouille la distinction entre ancienneté réelle du contenu et simple rafraîchissement de page, rendant la donnée d’origine difficile à interpréter.
Afin de garantir une fiabilité maximale sur la variable de date, nous avons mis en place un protocole de vérification stricte.
1. Présélection du jeu de données : Nous avons d’abord constitué un sous-ensemble de données dans lequel la variable updated_at indiquait une dernière mise à jour de moins de six mois.
2. Étape de récupération du site: Deux cas de figure ont été distingués :
● Lorsque la Wayback Machine donnait accès à un snapshot du site, nous avons utilisé la plus ancienne archive disponible afin d’extraire la date de publication à partir d’un contenu vérifiable et non actualisé.
● Lorsque la page n’était pas archivée, nous avons retenu la date de publication indiquée sur le site actuel, en considérant que l’absence d’archive récente signifiait probablement que le contenu avait été récemment mis en ligne.
3. Double vérification par outils indépendants : En complément, nous avons effectué deux passages pour chaque snapshots: une fois avec HTMLDate et une fois avec NewsPlease (qui reposent sur des algorithme distinct d’extraction de métadonnées temporelles)
4. Résultat du filtrage: Ce protocole a permis de constituer un jeu de données initial de 5 723 sources. Après vérification, ce nombre a été réduit à 827 sources jugées fiables sur leur date de publication. Un dernier filtrage, conservant uniquement les contenus publiés depuis moins de six mois, a abouti à un ensemble final de 676 observations. Parmi celles-ci, 98 % proviennent directement du site d’origine, sans passage par la Wayback Machine, ce qui confirme que les contenus récents ne sont généralement pas encore archivés.
Annexe


